
As fake news viraram polêmica na internet nos últimos anos. Na eleição para presidente nos EUA em 2016, hackers russos impulsionaram a divulgação de conteúdo que prejudicou a campanha de Hillary Clinton e favoreceu a vitória de Donald Trump. No Brasil, o WhatsApp se tornou a principal ferramenta para a disseminação de dados falsos envolvendo as eleições. De olho nesse fenômeno, um grupo de pesquisadores Instituto de Ciências Matemáticas e de Computação (ICMC) da Universidade de São Paulo (USP) e da Universidade Federal de São Carlos (UFSCar) desenvolveram uma plataforma para detectar notícias falsas.

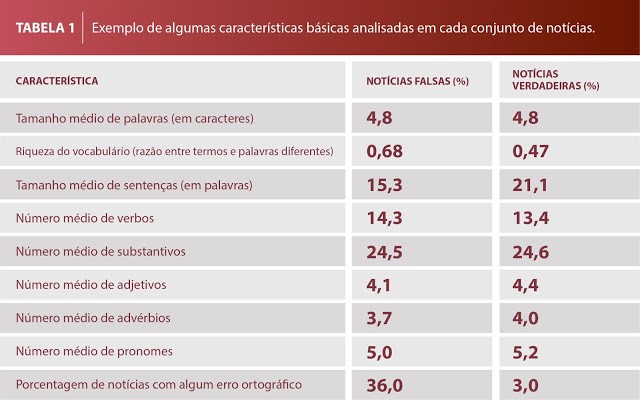
A plataforma usa estratégias de inteligência artificial para que o computador “aprenda” a identificar padrões de escrita das notícias. “Oferecemos ao computador um conjunto de 3.600 notícias verdadeiras e um conjunto de 3.600 notícias falsas. Uma vez que o computador aprende a distinção entre elas, ele aplica esse aprendizado para tentar predizer o tipo de novas notícias que o usuário fornece”, explica Thiago Pardo, coordenador do projeto e pesquisador do Núcleo Interinstitucional de Linguística Computacional (NILC) do ICMC. Os textos utilizados na pesquisa foram publicados na web entre janeiro de 2016 e janeiro de 2018, e podem ser consultados neste link.
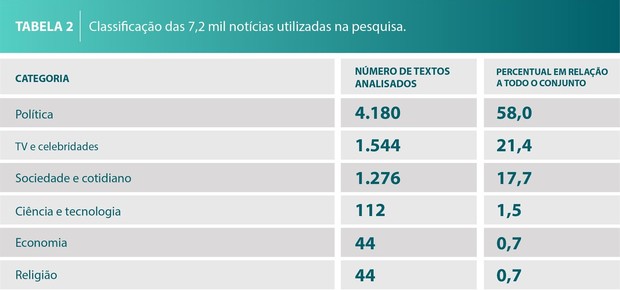
Roney Lira, aluno de doutorado em Ciência da Computação pelo ICMC e um dos autores do projeto, explica que um dos parâmetros relevantes para identificar notícias falsas na plataforma é a quantidade de erros ortográficos e advérbios. “Nos textos publicados pelos veículos jornalísticos, é bem difícil encontrarmos notícias com advérbios que expressem dúvida, por exemplo. Se uma notícia utiliza esses recursos em notícias factuais, podemos classifica-la como falsa”.
Outros parâmetros também são levados em consideração, como o número médio de substantivos, adjetivos e pronomes nos textos. A tecnologia também utiliza outros softwares para processamento de texto, como classificadores gramaticais, analisadores sintáticos e dicionários especializados.
Ainda em fase de aperfeiçoamento, a plataforma já pode ser acessada via web ou pelo WhatsApp. Ao acessar a página, o usuário deve inserir o texto da notícia a ser checada no campo indicado e que deve conter pelo menos 100 palavras, pois o sistema pode não funcionar corretamente com apenas partes de notícias. Se forem detectados indícios de que o texto seja falso, o sistema alertará: “Essa notícia pode ser falsa. Por favor, procure outras fontes confiáveis antes de divulgá-la”.
Utilizando métodos clássicos de machine learning, os pesquisadores conseguiram treinar o sistema com um índice de 90% de acerto na clafssificação de notícias. “Mas é preciso considerar que isso foi obtido em testes controlados de laboratório, com notícias inteiramente falsas ou verdadeiras”, explica Thiago Prado. “O mundo real, fora do laboratório, é bem mais desafiador”. Os próximos desafios, segundo ele, são analisar não apenas os padrões de escrita, mas novas estratégias de detecção de fake news com checagem automática de fatos.
Apesar do bom desempenho da plataforma na detecção de fake news, Thiago alerta que não acreditar prontamente em tudo o que lemos e a buscar por fontes confiáveis de notícias ainda são essenciais para a não propagação de notícias falsas. Ele ressalta também a importância de não delegar completamente para o computador a tarefa de separar notícias falsas das verdadeiras. “O software desenvolvido deve ser usado como um apoio para a seleção e filtragem de conteúdo, sendo que o usuário ainda deve fazer a checagem final”.
Financiado pelo Programa Institucional de Bolsas de Iniciação Científica (PIBIC) do CNPq e por outras duas agências de fomento brasileiras (CAPES e FAPESP), a tecnologia faz parte do projeto Detecção Automática de Notícias Falsas para o Português, que resultou na publicação do artigo Contributions to the Study of Fake News in Portuguese: New Corpus and Automatic Detection Results.





